





前言
吹爆这个博客:awesome-coding-js,强烈建议刷完这个博客
字符串
常用API:
操作方法。拼接concat(), 裁剪slice(), substr(), substring(),拆分变数组split(),repeat()(接收一个大于等于0的整数为参数,返回复制这个整数倍次数的字符串)
位置方法。indexof(), lastIndexof()
模式匹配方法。match()(接受一个正则做参数,返回匹配结果数组有), search()(少用), replace()(第一个参数是正则或字符串,第二个是用来替换的字符串。要实现多次替换必须是用带g的正则), startsWith()(用来检测字符串是否已制定的前缀开头,返回布尔值。接收一个或者两个参数,第一个是前缀,第二是开始查找的位置)
数组
常用API:
includes()。判断一个数组是否包含一个指定的值(接收这个值为参数,返回布尔值)
栈方法(先进后出):push(),pop()(会删除最后一项并作为返回值)
队列方法(先进先出):shift()(会删除第一项并作为返回值),unshift()(在数组前端添加任意个项并返回新数组的长度)
排序方法:reverse(), sort()(可以接收一个比较函数为参数,比较函数返回的值小于0,a会被排到b前面;没有传入比较函数,就只是单纯把数组toString(),然后用字符串的方法比较排序)
操作方法:concat()(拼接。返回新数组。不影响原来数组),slice()(裁剪。返回新数组。不影响原来数组。一个参数时返回该位置到末尾的所有项;两个参数时返回两个位置之间的项,但不包含结束位置的项),splice()(可删除,替换,插入。会影响原始数组。始终会返回一个数组,该数组包含从原始数组中删除的项)
位置方法:indexOf(),lastIndexOf()。找到的话将返回位置,没找到的话会返回-1
迭代方法
不生成数组的迭代
every():测试一个数组内的所有元素是否都能通过某个指定函数的测试。它返回一个布尔值。它的参数是一个返回值为布尔值的函数,所以用箭头函数表示很方便。
eg. [12, 5, 8, 130, 44].every(x => x >= 10); // false
some():同理,不过只要一个元素能通过就会返回true。
**reduce()**:累加器(骚操作神器),一定要return。对数值数组可以求和,对字符串数组相当于join()。更强大的功能见MDN的例子(累加对象里的键值;将二维数组转为一维;计算数组中每个元素出现的次数;按属性对Object分类;数组去重;绑定包含在对象数组中的数组)
eg. [1, 2, 3, 4].reduce((accumulator, currentValue) => accumulator + currentValue;) //将会得到10
reduceRight():同理,不过是从右往左开始累加
forEach()。很好用不解释
生成数组的迭代
map():和forEach类似。不过会返回新生成的数组(本来就是一个数组)保存操作结果
filter():和every()类似,不过会生成新数组来包含这些通过测试的item
借用apply
获取数组中最小值的方法: Math.min.apply(null, arr)
ES6
Array.from() 将类似数组的对象转为数组(arguement,Nodelist),也能将普通对象的key值取出来生成一个数组
正则
递归
说实话递归用的不溜
- 一般是一个数组保存结果,写一个递归函数,让这个函数执行一下,返回保存的结果
递归函数都喜欢设置第一个参数为暂时的处理结果(可以是数组),第二个参数是要处理的东西。递归函数内部,喜欢用if来判断终点,else来处理正常情况。这个正常情况最后都会递归一下。 - 递归函数内进行一些操作之后,最后再是边界判断决定是要return递归还是return结果。最终return也可以是递归函数的执行结果
排序算法
sort()虽然好用,但底层是一次完整的遍历排序,耗性能,做排序算法题能不用就不用。如果题目中要用数组的最大值/最小值,先想想能不能用冒泡/选择 排序。
比较
对于评述算法优劣术语的说明
稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面;
不稳定:如果a原本在b的前面,而a=b,排序之后a可能会出现在b的后面;
内排序:所有排序操作都在内存中完成;
外排序:由于数据太大,因此把数据放在磁盘中,而排序通过磁盘和内存的数据传输才能进行;
时间复杂度: 一个算法执行所耗费的时间。对于一个算法来说,可能会计算出如下操作次数 aN +1,N 代表数据量。那么该算法的时间复杂度就是 O(N)。因为我们在计算时间复杂度的时候,数据量通常是非常大的,这时候低阶项和常数项可以忽略不计。
空间复杂度: 运行完一个程序所需内存的大小。空间复杂度表示算法的存储空间与数据规模之间的增长关系。eg:
1 | function fun(n) { |
以上代码我们可以清晰的看出代码执行的空间为 O(1+n) = O(n),即为 i 及数组 a 占用的储存空间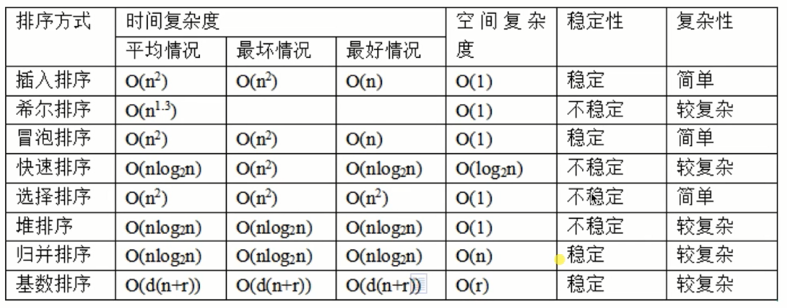
二分查找
一个排好序的数组,在其找item === flag的item的index。要start,end,middle
首先先找到长度中间位置,通过与中间位置的数比较,比中间值大在右边找,比中间值小在左边找。然后再在两边各自寻找中间值,持续进行,直到找到全部位置
1 | //假设arr已经排好序 |
非递归的方法也写一个吧
1 | function binarySearch(arr, flag) { |
冒泡排序(两两比较,大者排后)
冒泡排序的原理如下,从第一个元素开始,把当前元素和下一个索引元素进行比较。如果当前元素大,那么就交换位置,重复操作直到比较到最后一个元素,那么此时最后一个元素就是该数组中最大的数。下一轮重复以上操作,但是此时最后一个元素已经是最大数了,所以不需要再比较最后一个元素,只需要比较到 length - 1 的位置。实现代码如下:
1 | export default (arr) => { |
怎么实现降序? 将内层循环的if条件语句改为小于号即可
该算法的操作次数是一个等差数列 n + (n - 1) + (n - 2) + … + 1 ,去掉常数项以后得出时间复杂度是O(n * n)
选择排序(设置最小值索引)
选择排序的原理如下。遍历数组,设置最小值的索引为遍历的起始位置,如果取出的值比当前最小值小,就替换最小值索引,遍历完成后,将第一个元素和最小值索引上的值交换。如上操作后,第一个元素就是数组中的最小值,下次遍历就可以从索引 1 开始重复上述操作
口语化说法:遍历数组,找到最小值的元素放到数组的第一位;第二轮遍历,找到剩下的元素的最小值元素放到数组第二位;…(每次都能知道最小值)
1 | export default (arr) { |
快速排序
是利用二分查找对冒泡排序的改进,原理如下:随机选取一个数组中的值作为基准值,遍历数组把每项与基准值对比大小。比基准值小的放数组左边,大的放右边。然后将数组以基准值的位置分为两部分,继续递归以上操作
1 | function quickSort(arr) { |
插入排序(类似于摸扑克牌)
从第一个元素开始,该元素认为已经被排序了,取出下一个元素。在已经排序的元素序列中从后向前扫描,如果大于新元素,那么就把这个元素移动到下一个位置。直到找到已排序的元素小于或者等于新元素的位置,将新元素插入下一个位置。依次进行。(其实就是最开头的元素当作是有序数列,后面的元素是无序的,然后从第一个开始往前面插入)
1 | function insertSort(arr) { |
归并排序
一种稳定排序方法,将已有序的子序列合并,得到完全有序的序列,即先使每个子序列有序,再使序列段间有序。
其实也是二分的思想,只不过是在二分的基础上,先分段,段内再排,然后把每一段拼接起来。
这篇博客里有非常仔细的图片分析。这个需要新申请一个数组来做,所以自然是O(n)的空间复杂度啦
1 | function mergeSort(arr) { |
堆排序
见后面堆数据结构
栈
栈是一个线性结构,特点是只能在某一端添加或删除数据,遵循先进后出的原则。
实现:可以把栈看成是数组的一个子集,所以这里使用数组来实现
1 | class Stack { |
队列
队列是一个线性结构,特点是在某一端添加数据,在另一端删除数据,遵循先进先出的原则
单链队列的实现:用数组
1 | class Queue { |
因为单链队列在出队操作的时候需要 O(n) 的时间复杂度,所以引入了循环队列(也是LeetCode-622题目)。循环队列的出队操作平均是 O(1) 的时间复杂度。循环队列的一个好处是我们可以利用这个队列之前用过的空间。在一个普通队列里,一旦一个队列满了,我们就不能插入下一个元素,即使在队列前面仍有空间。但是使用循环队列,我们能使用这些空间去存储新的值。
可以看视频加深理解,实现代码如下:
1 | class MyCircularQueue { |
链表
链表和数组的区别
- 链表是链式的存储结构;数组是顺序的存储结构( 链表通过指针来连接元素与元素,数组则是把所有元素按次序依次存储)
- 链表的插入删除元素相对数组较为简单,不需要移动元素,但是寻找某个元素较为困难;数组寻找某个元素较为简单,但插入与删除比较复杂, 都需要把其他元素向前或者向后
概念
- 链表是一组由节点组成的集合,链表节点(也称数据元素的节点)又包含数据域(存数据)和指针域(指向下一个节点)。链表的尾元素指向一个null节点(为空)。eg. 可以简写为 Head->1->2->3->4->5->NULL
- 通常在在第一个节点前设置一个节点,称为头节点(不一定是必要元素,当是空表时可以是空)。其数据域可以无意义也可以存放链表长度等信息
- 链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但是链表失去了数组随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大
单向链表的实现
1 | class Node { // Node类表示节点 |
判断是否是环形链表(LeetCode-141)
1 | export default (head) => { |
反转链表(LeetCode-206),简单但是面试常问。可以画个图方便理解,需要三个变量(前,中,后)
注意不要弄混 反转 和 遍历。
1 | let exportFunction = (head) => { |
矩阵
在leetCode中一般是用二维数组表示,螺旋矩阵是面试常考题
树
树的定义:树由一组以边连接的节点组成。一些概念:根节点,左子树/右子树,子节点/父节点,叶子节点(最底部的节点),键值,从xx(节点)到xx的路径,树的层次(根节点是第0层),任何一层的节点都可以看做是子树的根
树的高度(从下往上)和深度(从上往下)。根节点的深度为1,叶子节点的高度为1
层数:根节点为第一层,往下一次递增
二叉树
一种特殊的树,子节点不超过两个。新增概念:左节点和右节点。
二叉搜索树(查找效率高)
特殊的二叉树。 每个节点的值都比他的左子树的值大,比右子树的值小。
其实已经是一种排序了。 因为二分搜索树的特性,父节点一定比所有左子节点大,比所有右子节点小(因为二叉搜索树就是由一堆数字经过函数之后构造的,所以一定满足这个定义)
给定一个数组,创建对应的二叉树和二叉搜索树,见 常见算法题及剑指offer
二叉搜索树的实现及其他操作
- 二叉搜索树的实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36class Node {
constructor(value) {
this.value = value
this.left = null
this.right = null
}
}
class BST {
constructor() {
this.root = null
this.size = 0
}
getSize() {
return this.size
}
isEmpty() {
return this.size === 0
}
addNode(v) {
this.root = this._addChild(this.root, v)
}
// 添加节点时,需要比较添加的节点值和当前
// 节点值的大小
_addChild(node, v) {
if (!node) {
this.size++
return new Node(v)
}
if (node.value > v) {
node.left = this._addChild(node.left, v)
} else if (node.value < v) {
node.right = this._addChild(node.right, v)
}
return node
}
} - 树的遍历
以上的这几种遍历都可以称之为深度遍历,对应的还有种遍历叫做广度遍历,也就是一层层地遍历树。对于广度遍历来说,我们需要利用之前讲过的队列结构来完成
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15breadthTraversal() {
if (!this.root) return null
let q = []
// 将根节点入队
q.push(this.root)
// 循环判断队列是否为空,为空代表树遍历完毕
while (q.length !== 0) {
// 将队首出队,判断是否有左右子树
// 有的话,就先左后右入队
let n = q.shift()
console.log(n.value)
if (n.left) q.push(n.left)
if (n.right) q.push(n.right)
}
} - 寻找最小值或最大数。因为二分搜索树的特性,所以最小值一定在根节点的最左边,最大值相反
1
2
3
4
5
6
7
8
9
10
11
12
13
14getMin() {
return this._getMin(this.root).value
}
_getMin(node) {
if (!node.left) return node
return this._getMin(node.left)
}
getMax() {
return this._getMax(this.root).value
}
_getMax(node) {
if (!node.right) return node
return this._getMin(node.right)
} - 最复杂的部分:删除节点。因为有三种情况:要删除的节点没有子树;有一条子树;两条子树
- 简单的情况:删除最小/最大的节点,下面以删除最小节点为例。对于删除最小节点来说,是不存在第三种情况的,删除最大节点操作是和删除最小节点相反的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15deleteMin() {
this.root = this._deleteMin(this.root)
console.log(this.root)
}
_deleteMin(node) {
// 一直递归找到最小节点
// 找到的时候判断时候有右节点,有的话就return右节点把原来的节点给重写了
// 没有右节点,也return右节点(null)重写原来节点,相当于删除了
if ((node != null) && !node.left) return node.right
node.left = this._deleteMin(this.left)
// 最后需要重新维护下节点的 `size`
node.size = this._getSize(node.left) + this._getSize(node.right) + 1
// 返回根节点
return node
} - 删除任意节点。思路:取出被删除节点右子树中最小的节点来替换被传出的节点。
当遇到这种情况时,需要取出当前节点的后继节点(也就是当前节点右子树的最小节点)来替换需要删除的节点。然后将需要删除节点的左子树赋值给后继结点,右子树删除后继结点后赋值给他。因为二分搜索树的特性,父节点一定比所有左子节点大,比所有右子节点小。那么当需要删除父节点时,势必需要拿出一个比父节点大的节点来替换父节点。这个节点肯定不存在于左子树,必然存在于右子树。然后又需要保持父节点都是比右子节点小的,那么就可以取出右子树中最小的那个节点来替换父节点1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31delect(v) {
this.root = this._delect(this.root, v)
}
_delect(node, v) {
if (!node) return null
// 寻找的节点比当前节点小,去左子树找
if (node.value < v) {
node.right = this._delect(node.right, v)
} else if (node.value > v) {
// 寻找的节点比当前节点大,去右子树找
node.left = this._delect(node.left, v)
} else {
// 进入这个条件说明已经找到节点
// 先判断节点是否拥有拥有左右子树中的一个
// 是的话,将子树返回出去,这里和 `_delectMin` 的操作一样
if (!node.left) return node.right
if (!node.right) return node.left
// 进入这里,代表节点拥有左右子树
// 先取出当前节点的后继结点,也就是取当前节点右子树的最小值
let min = this._getMin(node.right)
// 取出最小值后,删除最小值
// 然后把删除节点后的子树赋值给最小值节点
min.right = this._delectMin(node.right)
// 左子树不动
min.left = node.left
node = min
}
// 维护 size
node.size = this._getSize(node.left) + this._getSize(node.right) + 1
return node
}
- 简单的情况:删除最小/最大的节点,下面以删除最小节点为例。对于删除最小节点来说,是不存在第三种情况的,删除最大节点操作是和删除最小节点相反的。
堆
- 堆通常是一个可以被看做一棵树的数组对象(有索引),堆可以理解为有特殊特征的二叉树:必须是完全二叉树(n-1层必须是满二叉树),即除了最底层,其他层的节点都被元素填满;任一节点的值是其子树所有节点的最大值或最小值(称为最大堆/最小堆)

- 对任一索引为i的节点,其左子节点索引为
2*i + 1,右子节点为2*i + 2,父节点为(i-1) / 2 - 构建最大堆。即把一个普通的二叉树排序好变成一个最大堆。将节点与父节点对比大小,如果比父节点大,就和父节点交换位置(maxHeapify);遍历所有节点进行该操作之后就能构建一个最大堆。构建一次最大堆能选出一个最大值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56class Heap {
constructor(data) { // data应该是一个数组(保存未排序的二叉树)
this.data = data
}
sort() {
let iArr = this.data
let n = iArr.length
if (n <= 1) {
return iArr
} else {
for (let i = Math.floor(n / 2); i >= 0; i--) {// 构建最大堆从最后一个父节点开始循环
Heap.maxHeapify(iArr, i, n)
}
for (let j = 0; j < n; j++) {// 不断构建最大堆的过程
// 因为每次构建都会扔掉一个,所以是n-1-j
Heap.swap(iArr, 0, n - 1 - j)
// 每次交换位置扔完之后应该是从顶点开始,所以第二个参数是0
Heap.maxHeapify(iArr, 0, n - 1 - j - 1)
}
return iArr
}
}
// 交换两个元素
static swap(arr, a, b) {
if (a === b) {
return
}
let c = arr[a]
arr[a] = arr[b]
arr[b] = c
}
// 构建最大堆的过程
// 堆排序的时候需要把原来的根节点与最右的叶子节点互换位置后扔出数组,这里不是真的扔出去,而是引入了size,对索引大于size的item忽略不操作。
// 所以整个构建最大堆的过程数组的长度不会变
static maxHeapify(Arr, i, size) {
// i的左节点(索引),这是堆的固有规律
let l = i * 2 + 1
// i的右节点
let r = i * 2 + 2
let largest = i
// 父节点i和左节点l做比较取最大(此时只是比较并用largest变量保存最大的,并没有真正在数组中交换)
if (l <= size && Arr[l] > Arr[largest]) {
largest = l
}
// 父节点i和右节点r做比较取最大(此时只是比较并用largest变量保存最大的,并没有真正在数组中交换)
if (r <= size && Arr[r] > Arr[largest]) {
largest = r
}
// 在数组中交换
if (largest !== i) {
Heap.swap(Arr, i, largest)
// 交换完之后确保子树也是满足最大堆的条件
Heap.maxHeapify(Arr, largest, size)
}
}
} - 堆排序。在一次构建最大堆结束之后,把根节点与最右的叶子节互换位置(swap),然后移除现在这个叶子节点(原来的根节点)。再构建一次最大堆,即找到了第二大的值 … 直到最后只剩下一个节点,就完成了堆排序。
- 堆查找。见例题超级丑数。题意有点绕
堆和堆栈的概念区别
贪婪算法
贪心算法(又称贪婪算法,其实是一种思想)是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,他所做出的是在某种意义上的局部最优解
贪心算法不是对所有问题都能得到整体最优解,关键是贪心策略的选择,选择的贪心策略必须具备无后效性,即某个状态以前的过程不会影响以后的状态,只与当前状态有关
动态规划
概念
借助10级台阶有多少种走法(每次只能走一步或两步)的例子来理解。下面是重要概念:
- 状态转移方程。F(10) = F(9) + F(8)
- 最优子结构。F(10) = F(9) + F(8)。称F(9)和F(8)是F(10)的最优子结构
- 边界。往前推导的时候,会发现到F(1)和F(2)的之后就无法继续推导了,称这两者是问题的边界
总结:动态规划算法是通过拆分问题,定义问题状态和状态之间的关系,使得问题能够以递推(或者说分治)的方式去解决
解法:先观察题目写出状态转移方程,再判断问题的边界。特别善于解决不同路径和最短路径的问题
具体写法:构建数组(n+1) / 矩阵,填满已知部分(边界)(填满的过程也可以用for循环 (n+1) ),然后for循环设定好状态转移方程,最后return结构。用这种做法更好,递归容易超时?
见leetcode-62
自己的感想:见两道例题