





定义
哈希表 (散列表)
在线性表中,所有的数据都是顺序存储,当我们需要在线性表中查找某一数据时,当线性表过长,需要查找的数据排序比较靠后的话,就需要花费大量的时间,导致查找性能较差
所以我们可以把数据存在哈希表中,通过 key 去拿到数据。这个过程可以描述为:
拿到key(关键字) > 关键字通过散列函数(哈希函数)计算出来的值则称为散列值(哈希值、Hash 值) > 过散列值到**散列表(哈希表、Hash 表)**中就可以获取检索值
如下图: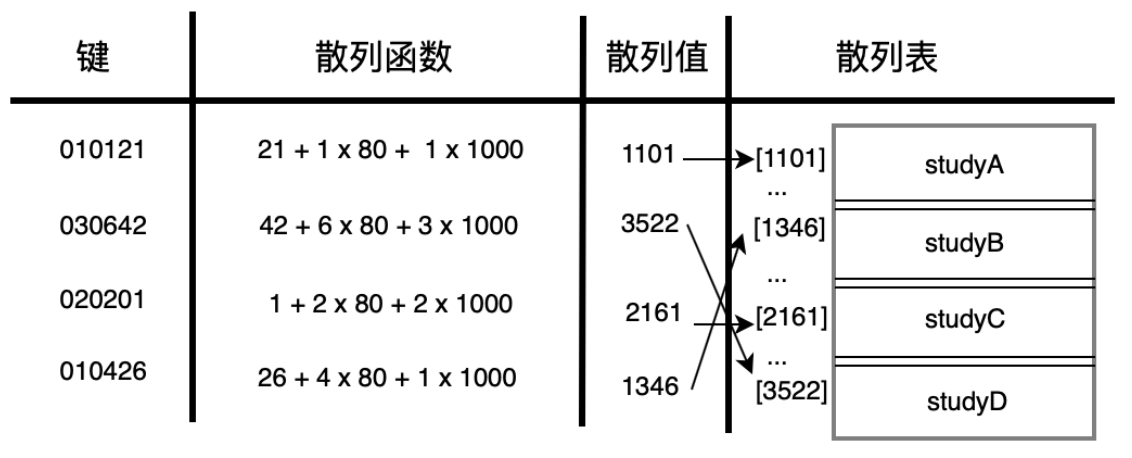
所以我们需要存的信息有:key,散列函数,散列表信息。所以,散列表是一种空间换时间的存储结构,是在算法中提升效率的一种比较常用的方式。
散列函数的作用就是给定一个键值,然后返回值在表中的地址:
1 | // 散列表 |
哈希函数
哈希函数(Hash Function),也称为散列函数或杂凑函数。哈希函数是一个公开函数,可以将任意长度的消息M映射成为一个长度较短且长度固定的值H(M),称H(M)为哈希值、散列值(Hash Value)、杂凑值或者消息摘要(Message Digest)。它是一种单向密码体制,即一个从明文到密文的不可逆映射,只有加密过程,没有解密过程。
它的函数表达式为:h = H(m)
无论输入是什么数字格式、文件有多大,输出都是固定长度的比特串。eg. 以比特币使用Sh256算法,无论输入是什么数据文件,输出就是256bit。
每个bit就是一位0或者1,256bit就是256个0或者1二进制数字串,用16进制数字表示的话: 16等于2的4次方,所以每一位16进制数字可以代表4位bit,所以256位bit用16进制数字表示是256除以4等于64位。
于是我们通常看到的哈希值,是这样的:
00740f40257a13bf03b40f54a9fe398c79a664bb21cfa2870ab07888b21eeba8
特点
- 易压缩:对于任意大小的输入x,Hash值的长度很小,在实际应用中,函数H产生的Hash值其长度是固定的。
- 易计算:对于任意给定的消息,计算其Hash值比较容易。
- 单向性:对于给定的Hash值,要找到使得在计算上是不可行的,即求Hash的逆很困难。在给定某个哈希函数H和哈希值H(M)的情况下,得出M在计算上是不可行的。即从哈希输出无法倒推输入的原始数值。这是哈希函数安全性的基础。
- 抗碰撞性:理想的Hash函数是无碰撞的,但在实际算法的设计中很难做到这一点。有两种抗碰撞性:一种是弱抗碰撞性,即对于给定的消息,要发现另一个消息,满足在计算上是不可行的;另一种是强抗碰撞性,即对于任意一对不同的消息,使得在计算上也是不可行的。
- 高灵敏性:这是从比特位角度出发的,指的是1比特位的输入变化会造成1/2的比特位发生变化。消息M的任何改变都会导致哈希值H(M)发生改变。即如果输入有微小不同,哈希运算后的输出一定不同。
哈希算法的要求
一个可靠的哈希算法,应该满足:
- 对于给定的数据M,很容易算出哈希值X=F(M);根据X很难反算出M
- 很难找到M和N使得F(N)=F(M)(这个可能是加密领域的,其实在储存领域,为了节省空间,key 值不同,通过散列函数计算出来的散列值(value)不一定不相同)
哈希函数更多设计方法和冲突解决方法详见哈希表问题
一个简单的例子
一个初始值值对应一个唯一的结果值,根据结果还推算不出来初始值,这可以通过丢掉一部分信息的加密方式实现,称为“单向加密”,也叫哈希算法。一个简单的例子:取注册者注册的时间戳的后6位再乘6取后6位,勉勉强强可以算是一个哈希算法。
常见的哈希算法(加密领域)
- SHA-1算法
- SHA-2算法
- SHA-512算法
- SHA-3算法
- RIPEMD160算法
- …
这些算法的过程大概包括:输入 > 消息填充 > 链接变量初始化 > 处理主循环模块 > 得出最终的Hash值
算法的具体细节见哈希算法