





感受:这本书更偏向于讲 NodeJS 的大纲和原理。所以本笔记只讲原理和case,对于API不熟的请翻文档,或看小卡的笔记, 或看poetries的笔记
第一章 Node 简介
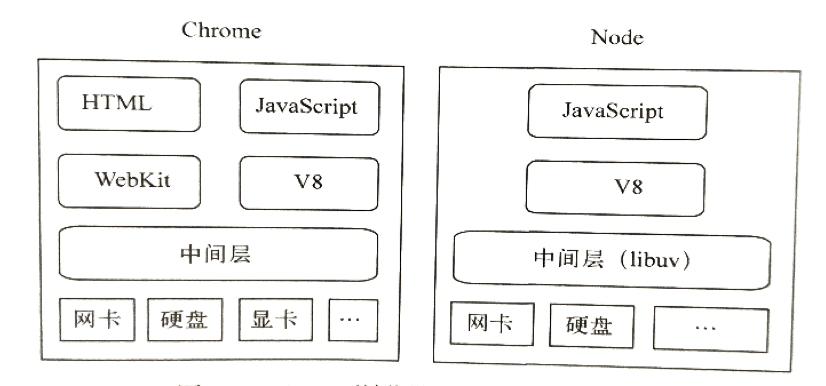
Chrome 浏览器的组成和 Node 的组件组成
Node 的特点
- 异步 I/O。eg. Ajax, fs.readFile 等,Node 中绝大数的操作都以异步的方式进行调用
- 事件与回调函数。将前端中广泛成熟点时间机制引入后端,配合 IO 使用,eg. 监听 request 事件,然后执行回调函数
- 单线程。保留了 JS 在浏览器中单线程的特点
- 优点:不用在意状态的同步问题,没有死锁的存在,也没有上下文交互的性能开销
- 弱点:
- 无法利用多核 CPU
- 错误会引起整个应用退出,代码健壮性值得考验
- 大量计算占用 CPU 无法继续调用异步 I/O。eg. 长时间的 CPU 占用会导致后续的异步 IO 发不出调用。浏览器中类似的问题被 Web Worker 解决,Node 也采用类似的思路:子进程 child_process
- 子进程的出现可以解决单线程在健壮性和无法利用多核 CPU 的问题。通过将计算分发到各个子进程,可以将大量斤算分解掉,再通过进程的事件消息来传递结果,可很好地保持应用模型的简单和依赖;通过 Master-Worker 的管理方式,也可以很好地管理各个工作的进程,以达到更高的健壮性
- 跨平台。Node 基于 libuv 实现跨平台,可以在 Linux,Window 使用。它在操作系统和 Node 上层模块系统之间构建了一层平台层架构,即 libuv。libux 也是许多系统实现跨平台的基础组件
应用场景
- I/O 密集
- CPU 密集是否不合适?Node 没有提供多线程用于计算支持,但是仍有两个方式充分利用 CPU:
- Node 可以通过编写 C++扩展的方式提高 CPU 利用,将一些 V8 不能做到性能极致的地方用 C++来实现
- 用子进程的方式,将一部分进程用来计算,然后用进程通信传递结果,将计算和 I/O 分离
应用好处
用 Node 做 Web 开发,前端工程师在 HTTP 协议栈的两端能高效灵活开发,避免了 Java 的繁琐;另一方面,又利用 Java 作为后端接口和中间件,使其有良好的稳定性。两者取长补短
第二章 模块机制
CommonJS 规范
解决 JS 弱结构性的问题,愿景:希望 JS 能在任何地方运行
eg.
1 | const math = require(‘math’) |
Node 模块的实现
引入模块的实现步骤:
- 路径分析
- 文件定位
- 编译执行
Node 提供的模块称为核心模块;用户编写的模块称为文件模块。都会优先从缓存加载 Module._cache;缓存的是 Node 编译和执行后的对象
模块编译
核心模块部分在 Node 源代码的变异过程中,编译进了二进制执行文件;启动时就被直接加载进内存中;而文件模块是在运行时动态加载,需要完成走上述三个流程
定位到具体文件后,Node 会新建一个模块对象,然后根据路径载入并编译。对不同的文件扩展名,载入方式不同:
- .js。通过 fs 模块读取文件后编译执行
- .node。这是 C/C++编写的扩展文件,通过 process.dlopen()方法加载最后编译生成的文件(但其实 C/C++模块不用编译,它本来就是编译好的)。C/C++模块的优势是执行效率;但显然 JS 编写的模块开发速度更快
- .json。fs 模块读取后,用 JSON.parse()解析返回结果
- 其他。都被当成.js
核心模块 & 编译 & 编写核心模块
核心模块分为 C/C++编写的和 JS 编写的两部分。Node 的 buffer,crypto,evals,fs,os 等模块都是部分通过 C/C++编写的
C/C++扩展模块 & 加载 & 编写
CPU 性能更加
模块调用栈
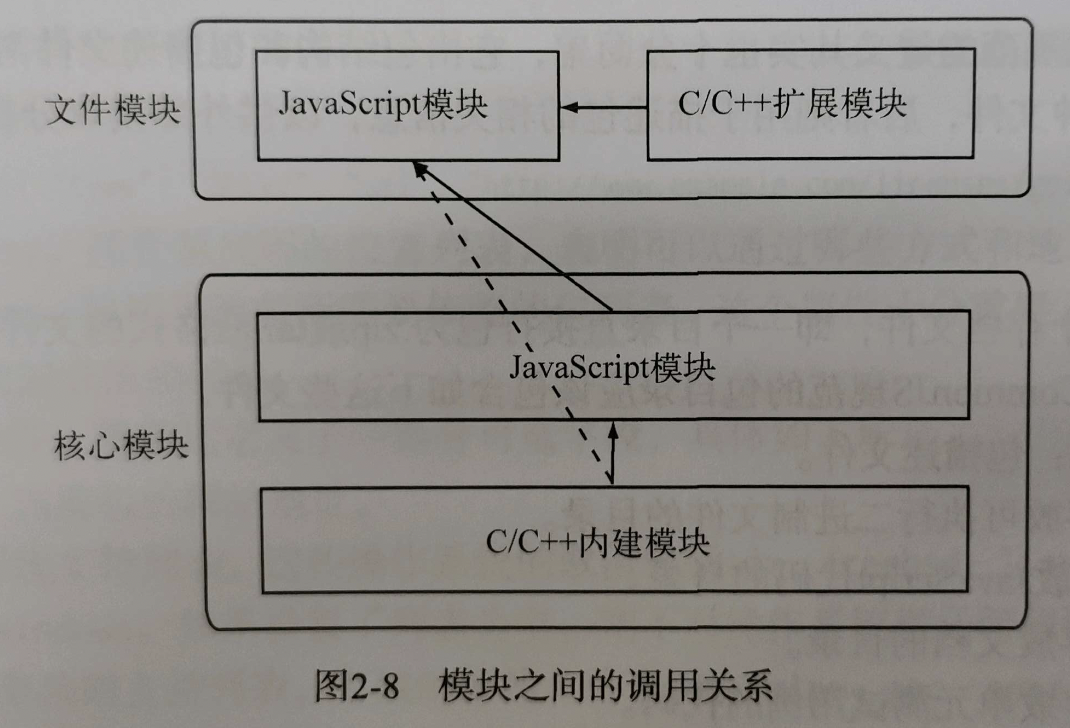
包和 NPM
在模块之外,包和 NPM 是将模块联系起来的一种机制,是在模块的基础上进一步组织 JS 代码。包结构如下:
- package.json
- bin。存放可执行的二进制文件
- lib。存放 JS 代码
- doc
- test。单元测试用例
已经很少用的 AMD 和 CMD 规范
第三章 异步 I/O
异步 I/O 实现现状
阻塞 IO 造成 CPU 等待浪费,非阻塞带来的麻烦事需要轮训去确认是否完成数据获取,它会让 CPU 处理状态判断,是对 CPU 资源的浪费
轮询的五种方案:read, select,poll, epoll(效率最高), kqueue。见 P53
Node 的异步 IO
事件循环、观察者、请求对象、I/O 线程池这四者共同构建成了 Node 异步 I/O 模型的基本要素
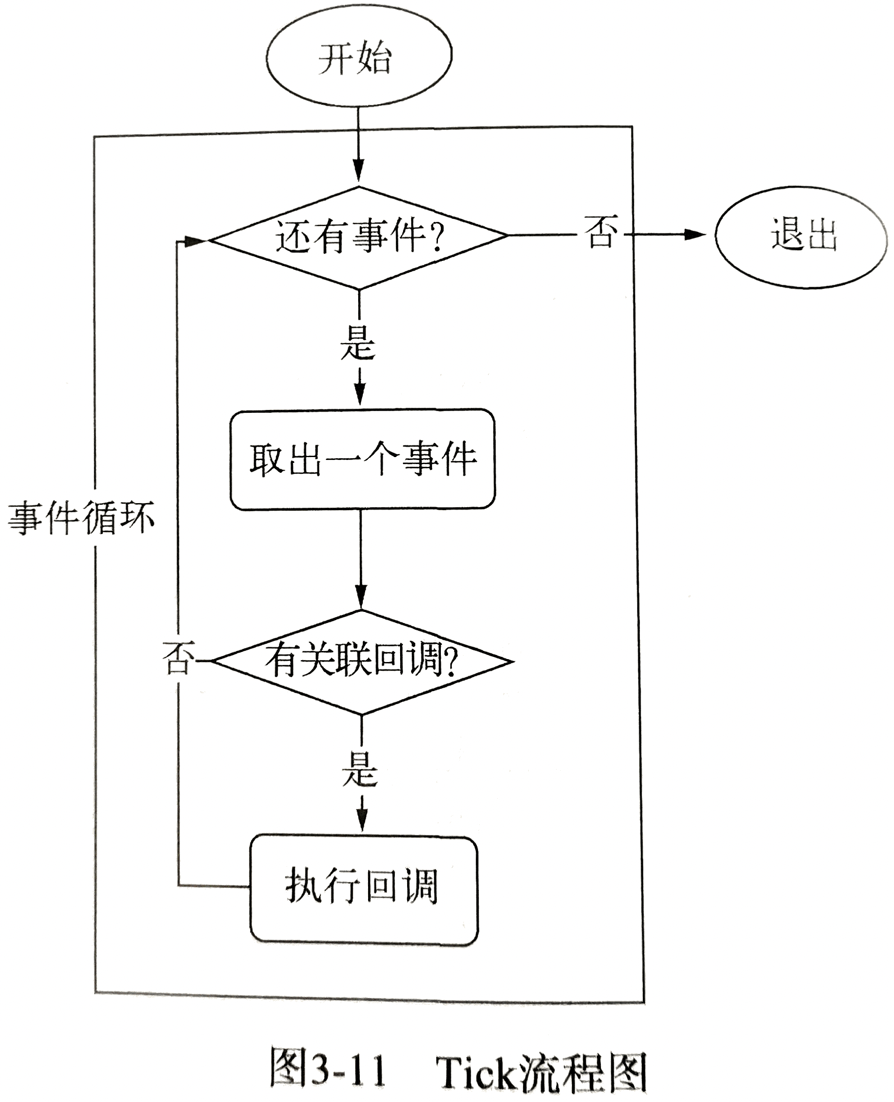
事件循环是异步实现的核心
- Node 自身的执行模型是事件循环,正是它使得回调函数十分普遍。进程启动的时候,Node 会创建一个类似 whlie 的循环,每执行一次循环体的过程我们称为 Tick。如下图
- (还有事件?) 那里即是观察者
请求对象 和 I/O 线程池
没太看懂。反正整个异步 IO 流程如下:
输入输出完成端口(Input/Output Completion Port,IOCP)
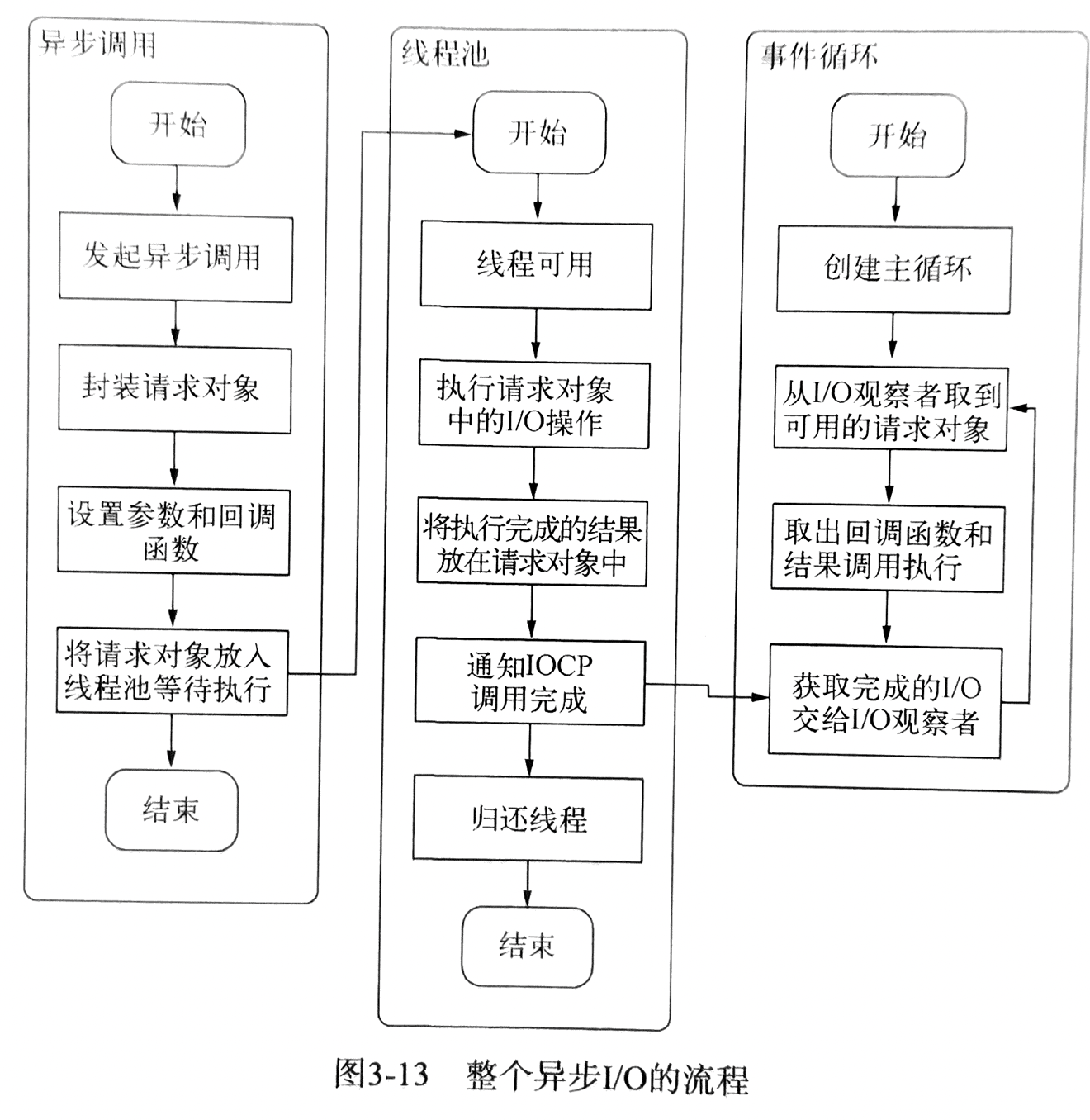
- 这里的单线程与 IO 线程池看起来有些悖论的杨祖。由于我们知道 JS 是单线程的,所以按常识容易理解为它不能充分利用多核 CPU。事实上,在 Node 中,除了 JS 是单线程外,Node 自身其实是多线程的,只是 IO 线程使用的 CPU 较少
- 另一点需要重视的观点则是,除了用户代码无法并行执行外,所有的 IO(磁盘 IO 和网络 IO 等)则是可以并行起来的
非 IO 的异步 API
Node 中与 IO 无关的异步 API:setTimeout(), setInterval(), setImmediate(), process.nextTick()
定时器
setTimeout()和 setInterval()和浏览器中是一致的,分别用于单次和多次定时执行任务。
- 原理。它们的原理与异步 IO 比较类似,只是不需要 IO 线程池的参与。调用 setTimeout()或 setInterval()创建的定时器会被插入到定时器观察者内部的一个红黑树中。每次 Tick 执行时,会从该红黑树中迭代去除定时器对象,检查是否超过时间,如果超过,就形成一个事件,它的回调函数将立即执行。这个过程包含动用红黑树,创建定时器对象和迭代等操作,较为浪费性能
- 问题。它并非精准的。尽管时间循环十分快,但是如果某一次循环占用的时间较多,那么下次循环时,它也许已经超时很久了。eg. 通过 setTimeout 设定一个任务在 10ms 后执行,但是在 9ms 后,有一个任务占用了 5ms 的 CPU 时间片,再次轮到定时器执行时,时间就已经过期 4ms 了
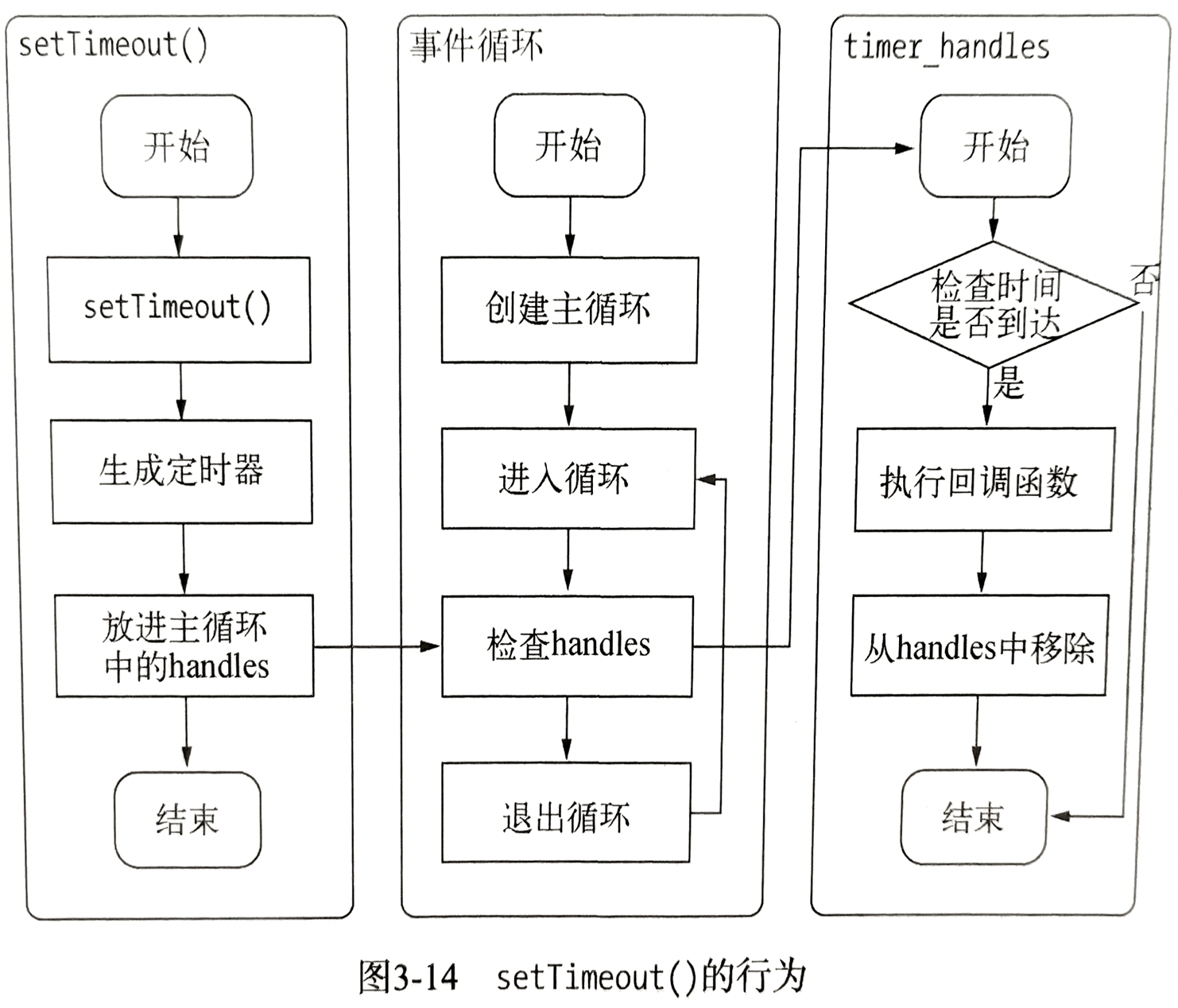
process.nextTick() 和 setImmediate()
- 每次调用 process.nextTick 函数,只会将回调函数放入队列中,在下一轮 Tick 的时候取出运行。定时器中采用红黑树操作的时间复杂度为 O(lg(n)), 而 nextTick 为 O(1),更为高效
- setImmediate()和 process.nextTick 十分类似,都是将回调函数延迟执行。但是执行优先级没 process.nextTick 高。似乎都属于微任务?
事件驱动与高性能服务器
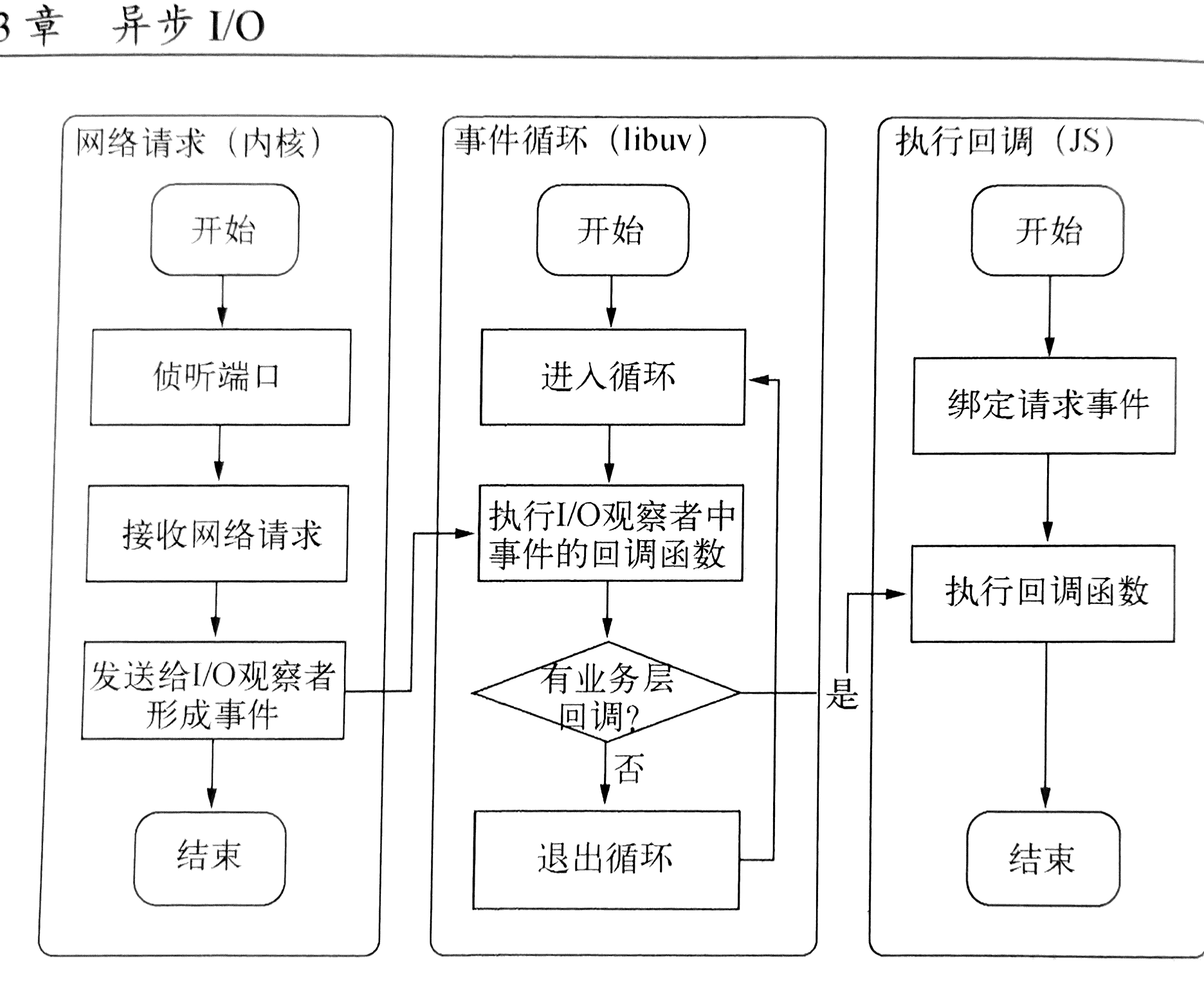
图3-15 利用Node构建Wen服务器的流程图
第四章 异步编程
函数式编程
- 高阶函数:可以把函数作为参数,或是将函数作为返回值的函数。eg. JS中的forEach, some, reduce等
- 偏函数:指创建一个调用另外一个部分——参数或变量已经预置的函数——的函数的用法。个人理解:偏函数会返返回一个函数,返回的函数的一部分是由偏函数的参数生成的。eg. 封装一个判断类型的函数
1
2
3
4
5
6
7let isType = function(type) {
return function(obj) {
return Object.toString.call(obj) === '[object ' + type + ']'
}
}
Let isString = isType('String')
isString('test') // true
异步编程的优势和难点
- 优势:基于时间驱动的非阻塞IO模型
- 难点
- 异常处理
- 函数嵌套太深
- 阻塞代码
- 多线程的编程。有了child_process
- 异步转同步